
A curated list of delightful Unicode tidbits, packages and resources.
Please read the contribution guidelines before contributing. Key Unicode terminology is defined in the glossary.
Cross posted to Wisdom’s Dev Blog
Unicode is Awesome! Prior to Unicode, international communication was grueling- everyone had defined their separate extended character set in the upperhalf of ASCII (called Code Pages) that would conflict- Just think, German speakers coordinating with Korean speakers over which 127 character Code Page to use. Thankfully the Unicode standard caught on and unified communication. Unicode 8.0 standardizes over 120,000 characters from over 129 scripts - some modern, some ancient, and some still undeciphered. Unicode handles left-to-right and right-to-left text, combining marks, and includes diverse cultural, political, religious characters and emojis. Unicode is awesomely human - and ultimately underappreciated.
The Unicode Standard defines codes for characters used in all the major languages written today. Scripts include the European alphabetic scripts, Middle Eastern right-to-left scripts, and many scripts of Asia.
The Unicode Standard further includes punctuation marks, diacritics, mathematical symbols, technical symbols, arrows, dingbats, emoji, etc. It provides codes for diacritics, which are modifying character marks such as the tilde (~), that are used in conjunction with base characters to represent accented letters (ñ, for example). In all, the Unicode Standard, Version 9.0 provides codes for 128,172 characters from the world’s alphabets, ideograph sets, and symbol collections.
The majority of common-use characters fit into the first 64K code points, an area of the codespace that is called the basic multilingual plane, or BMP for short. There are sixteen other supplementary planes available for encoding other characters, with currently over 850,000 unused code points. More characters are under consideration for addition to future versions of the standard.
The Unicode Standard also reserves code points for private use. Vendors or end users can assign these internally for their own characters and symbols, or use them with specialized fonts. There are 6,400 private use code points on the BMP and another 131,068 supplementary private use code points, should 6,400 be insufficient for particular applications.
Character encoding standards define not only the identity of each character and its numeric value, or code point, but also how this value is represented in bits.
The Unicode Standard defines three encoding forms that allow the same data to be transmitted in a byte, word or double word oriented format (i.e. in 8, 16 or 32-bits per code unit). All three encoding forms encode the same common character repertoire and can be efficiently transformed into one another without loss of data. The Unicode Consortium fully endorses the use of any of these encoding forms as a conformant way of implementing the Unicode Standard.
UTF-8 is popular for HTML and similar protocols. UTF-8 is a way of transforming all Unicode characters into a variable length encoding of bytes. It has the advantages that the Unicode characters corresponding to the familiar ASCII set have the same byte values as ASCII, and that Unicode characters transformed into UTF-8 can be used with much existing software without extensive software rewrites.
UTF-16 is popular in many environments that need to balance efficient access to characters with economical use of storage. It is reasonably compact and all the heavily used characters fit into a single 16-bit code unit, while all other characters are accessible via pairs of 16-bit code units.
UTF-32 is useful where memory space is no concern, but fixed width, single code unit access to characters is desired. Each Unicode character is encoded in a single 32-bit code unit when using UTF-32.
All three encoding forms need at most 4 bytes (or 32-bits) of data for each character.
The Unicode characterset is divided into 17 core segments called “planes”, which are further divided into blocks. Each plane has space for 65,536 (2¹⁶) codepoints, supporting a grand total of 1,114,112 codepoints. There are two “Private Use Area” planes (#16 & #17) that are allocated to be used however one wishes. These two Private Use planes account for 131,072 codepoints.
| # | Name | Range |
|---|---|---|
| 1. | Basic Multilingual Plane | (U+0000 to U+FFFF) |
| 2. | Supplementary Multilingual Plane | (U+10000 to U+1FFFF) |
| 3. | Supplementary Ideographic Plane | (U+20000 to U+2FFFF) |
| 4. | Tertiary Ideographic Plane | (U+30000 to U+3FFFF) |
| 5. | Plane 5 (unassigned) | (U+40000 to U+4FFFF) |
| 6. | Plane 6 (unassigned) | (U+50000 to U+5FFFF) |
| 7. | Plane 7 (unassigned) | (U+60000 to U+6FFFF) |
| 8. | Plane 8 (unassigned) | (U+70000 to U+7FFFF) |
| 9. | Plane 9 (unassigned) | (U+80000 to U+8FFFF) |
| 10. | Plane 10 (unassigned) | (U+90000 to U+9FFFF) |
| 11. | Plane 11 (unassigned) | (U+A0000 to U+AFFFF) |
| 12. | Plane 12 (unassigned) | (U+B0000 to U+BFFFF) |
| 13. | Plane 13 (unassigned) | (U+C0000 to U+CFFFF) |
| 14. | Plane 14 (unassigned) | (U+D0000 to U+DFFFF) |
| 15. | Supplementary Special-purpose Plane | (U+E0000 to U+EFFFF) |
| 16. | Supplementary Private Use Area - A | (U+F0000 to U+FFFFF) |
| 17. | Supplementary Private Use Area - B | (U+100000 to U+10FFFF) |
The first plane is called the Basic Multilingual Plane or BMP. It contains the code points from U+0000 to U+FFFF, which are the most frequently used characters. The other sixteen planes (U+010000 → U+10FFFF) are called supplementary planes or astral planes.
Characters outside the BMP, e.g. U+1D306 tetragram for centre (𝌆), can only be encoded in UTF-16 using two 16-bit code units: 0xD834 0xDF06. This is called a surrogate pair. Note that a surrogate pair only represents a single character. The first code unit of a surrogate pair is always in the range from 0xD800 to 0xDBFF, and is called a high surrogate or a lead surrogate. The second code unit of a surrogate pair is always in the range from 0xDC00 to 0xDFFF, and is called a low surrogate or a trail surrogate.
Surrogate pair: A representation for a single abstract character that consists of a sequence of two 16-bit code units, where the first value of the pair is a high-surrogate code unit and the second value is a low-surrogate code unit. Surrogate pairs are used only in UTF-16. (See Section 3.9, Unicode Encoding Forms.) – Unicode 8.0.0 Chapter 3 - Surrogates
The Unicode character 💩 Pile of Poo (U+1F4A9) in UTF-16 must be encoded as a surrogate pair, i.e. two surrogates. To convert any code point to a surrogate pair, use the following algorithm (in JavaScript). Keep in mind that we’re using hexidecimal notation.
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 };
var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
// Reverses The Conversion
var Code_Point = function(High_Surrogate, Low_Surrogate){
return (High_Surrogate - 0xD800) * 0x400 + Low_Surrogate - 0xDC00 + 0x10000;
}; > var codepoint = 0x1F4A9; // 0x1F4A9 == 128169
> High_Surrogate(codepoint).toString(16)
"d83d" // 0xD83D == 55357
> Low_Surrogate(codepoint).toString(16)
"dca9" // 0xDCA9 == 56489
> String.fromCharCode( High_Surrogate(codepoint) , Low_Surrogate(codepoint) );
"💩"
> String.fromCodePoint(0x1F4A9)
"💩"
> '\ud83d\udca9'
"💩"Unicode includes a mechanism for modifying character shape that greatly extends the supported glyph repertoire. This covers the use of combining diacritical marks. They are inserted after the main character. Multiple combining diacritics may be stacked over the same character. Unicode also contains precomposed versions of most letter/diacritic combinations in normal use.
Certain sequences of characters can also be represented as a single character, called a precomposed character (or composite or decomposible character). For example, the character “ü” can be encoded as the single code point U+00FC “ü” or as the base character U+0075 “u” followed by the non-spacing character U+0308 “¨”. The Unicode Standard encodes precomposed characters for compatibility with established standards such as Latin 1, which includes many precomposed characters such as “ü” and “ñ”.
Precomposed characters may be decomposed for consistency or analysis. For example, in alphabetizing (collating) a list of names, the character “ü” may be decomposed into a “u” followed by the non-spacing character “¨”. Once the character has been decomposed, it may be easier for the collation to work with the character because it can be processed as a “u” with modifications. This allows easier alphabetical sorting for languages where character modifiers do not affect alphabetical order. The Unicode Standard defines the decompositions for all precomposed characters. It also defines normalization forms to provide for unique representations of characters.
From Mark Davis’s Unicode Myths slides. - Unicode is simply a 16-bit code - Some people are under the misconception that Unicode is simply a 16-bit code where each character takes 16 bits and therefore there are 65,536 possible characters. This is not, actually, correct. It is the single most common myth about Unicode, so if you thought that, don’t feel bad.
You can use any unassigned codepoint for internal use - No. Eventually that hole will be filled with a different character. Instead use private use or noncharacters.
Every Unicode code point represents a character - No. There are lots of nonCharacters (FFFE, FFFF, 1FFFE,…) There are also surrogate code points, private and unassigned codepoints, and control/format “characters” (RLM, ZWNJ,…)
Unicode will run out of space - If it were linear, we would run out in 2140 AD. But it isn’t linear. See http://www.unicode.org/roadmaps/
| Encoding Type | Raw Encoding |
|---|---|
| HTML Entity (Decimal) | 🖖 |
| HTML Entity (Hexadecimal) | 🖖 |
| URL Escape Code | %F0%9F%96%96 |
| UTF-8 (hex) | 0xF0 0x9F 0x96 0x96 (f09f9696) |
| UTF-8 (binary) | 11110000:10011111:10010110:10010110 |
| UTF-16/UTF-16BE (hex) | 0xD83D 0xDD96 (d83ddd96) |
| UTF-16LE (hex) | 0x3DD8 0x96DD (3dd896dd) |
| UTF-32/UTF-32BE (hex) | 0x0001F596 (0001f596) |
| UTF-32LE (hex) | 0x96F50100 (96f50100) |
| Octal Escape Sequence | \360\237\226\226 |
| Encoding Type | Raw Encoding |
|---|

The Unicode Consortium published a general punctuation chart where you can find more details.
| Char | Name | Description |
|---|---|---|
'' |
U+FEFF (Byte Order Mark - BOM) | has the important property of unambiguity on byte reorder. It is also zerowidth, and invisible. In non-complying software (like the PHP interpreter) this leads to all sorts of fun behaviour. |
'' |
‘\uFFEF’ Reversed Byte Order Mark (BOM) | does not equate to a legal character, other than the beginning of text. |
'' |
‘\u200B’ zero-width non-break space | (a character with no appearance and no effect other than preventing the formation of ligatures). |
' ' |
U+00A0 NO-BREAK SPACE |
force adjacent characters to stick together. Well known as
in HTML.
|
'' |
U+00AD SOFT HYPHEN | (in HTML: ) like ZERO WIDTH SPACE, but show a hyphen if (and only if) a break occurs. |
'' |
U+200D ZERO WIDTH JOINER | force adjacent characters to be joined together (e.g., arabic characters or supported emoji). Can be used this to compose sequentially combined emoji. |
'' |
U+2060 WORD JOINER | the same as U+00A0, but completely invisible. Good for writing @font-face on Twitter. |
' ' |
U+1680 OGHAM SPACE MARK | a space that looks like a dash. Great to bring programmers close to madness: 1 + 2 === 3. |
';' |
U+037E GREEK QUESTION MARK | a look-alike to the semicolon. Also a fun way to annoy developers. |
'' |
U+202D | change the text direction to Left-to-Right. |
'' |
U+202E | change the text direction to Right-to-Left: |
'ꓸ' |
U+A4F8 LISU LETTER TONE MYA TI | A lookalike for the period character. |
'ꓹ' |
U+A4F9 LISU LETTER TONE NA PO | A lookalike for the comma character. |
'ꓼ' |
U+A4FC LISU LETTER TONE MYA NA | A lookalike for the semi-colon character. |
'ꓽ' |
U+A4FD LISU LETTER TONE MYA JEU | A lookalike for the colon character. |
'︀' |
Variation Selectors ( U+FE00 to U+FE0F & U+E0100 to U+E01EF ) | a block of 256 zero width characters that posess the ID_Continue proprerty- meaning they can be used in variable names (not the first letter). What makes these special is the fact that mouse cursors pass over them as they are combining characters - unlike most other zero width characters. |
'ᅟ' |
U+115F HANGUL CHOSEONG FILLER | In general it produces a space. Rendered as zero width (invisible) if not explicitly supported in rendering. Designated ID_Start |
'ᅠ' |
U+1160 HANGUL JUNGSEONG FILLER | Perhaps it produces a space? Rendered as zero width (invisible) if not explicitly supported in rendering. Designated ID_Start |
'ㅤ' |
U+3164 HANGUL FILLER | In general it produces a space. Rendered as zero width (invisible) if not explicitly supported in rendering. Designated ID_Start |
#### Wait a second… what did I just read?
## Variable identifiers can effectively include whitespace!
The U+3164 HANGUL FILLER character displays as an advancing whitespace character. The character is rendered as completely invisible (and non advancing, i.e. “zero width”), if not explicitly supported in rendering. That means the ugly character replacement (�) symbol should never be displayed.
I’m not yet sure why U+3164 was specified to behave this way. Interestingly, U+3164 was added to Unicode in version 1.1 (1993)- so the consortium must have had a lot of time to think it through. Anyway, here are a few examples.
> var ᅟ = 'foo';
undefined
> ᅟ
'foo'
> var ㅤ= alert;
undefined
> var foo = 'bar'
undefined
> if ( foo ===ㅤ`baz` ){} // alert
undefined
> var varㅤfooㅤ\u{A60C}ㅤπ = 'bar';
undefined
> varㅤfooㅤꘌㅤπ
'bar'
NOTE: I’ve tested U+3164 rendering on Ubuntu and OS X
with the following: node, php,
ruby, python3.5,
scala ,vim, cat,
chrome+github gist. Atom is the only system that
fails by (incorrectly) displaying empty boxes. I have yet to test it out
on Emacs and Sublime. From what I understand, the Unicode Consortium will
not reassign or rename characters or codepoints, but may be convinced to
change character properties like ID_Start/ID_Continue.
The zero-width joiner (ZWJ) is a non-printing character used in the computerized typesetting of some complex scripts such as the Arabic script or any Indic script. When placed between two characters that would otherwise not be connected, a ZWJ causes them to be printed in their connected forms.
The zero-width non-joiner (ZWNJ) is a non-printing character used in the computerization of writing systems that make use of ligatures. When placed between two characters that would otherwise be connected into a ligature, a ZWNJ causes them to be printed in their final and initial forms, respectively. This is also an effect of a space character, but a ZWNJ is used when it is desirable to keep the words closer together or to connect a word with its morpheme.
> 'a'
"a"
> 'a\u{0308}'
"ä"
> 'a\u{20DE}\u{0308}'
"a⃞̈"
> 'a\u{20DE}\u{0308}\u{20DD}'
"a⃞̈⃝"
// Modifying Invisible Characters
> '\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}'
""
> '\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}\u{200E}'.length
10| Char | Code Point | Output Char |
|---|---|---|
| ß | 0x00DF | SS |
| ı | 0x0131 | I |
| ſ | 0x017F | S |
| ff | 0xFB00 | FF |
| fi | 0xFB01 | FI |
| fl | 0xFB02 | FL |
| ffi | 0xFB03 | FFI |
| ffl | 0xFB04 | FFL |
| ſt | 0xFB05 | ST |
| st | 0xFB06 | ST |
| Char | Code Point | Output Char |
|---|---|---|
| K | 0x212A | k |
String length is typically determined by counting
codepoints.
This means that surrogate pairs would count as two characters.
Combining multiple diacritics may be stacked over the same character.
a + ̈ == ̈a, increasing length, while only producing a
single character.
Similarily, reversing strings often is a non-trivial task. Again, surrogate pairs and diacritics must be reversed together. ES Reverser provides a pretty good solution.
Most of the below characters express their one-to-many case mappings when uppercased- while others should be lowercased. This list should be split up
| Code Point | Character | Name | Mapped Character | Mapped Code Points |
|---|---|---|---|---|
| U+00DF | ß |
LATIN SMALL LETTER SHARP S | s, s |
U+0073, U+0073 |
| U+0130 | İ |
LATIN CAPITAL LETTER I WITH DOT ABOVE | i, ̇ |
U+0069, U+0307 |
| U+0149 | ʼn |
LATIN SMALL LETTER N PRECEDED BY APOSTROPHE | ʼ, n |
U+02BC, U+006E |
| U+01F0 | ǰ |
LATIN SMALL LETTER J WITH CARON | j, ̌ |
U+006A, U+030C |
| U+0390 | ΐ |
GREEK SMALL LETTER IOTA WITH DIALYTIKA AND TONOS | ι, ̈, ́ |
U+03B9, U+0308, U+0301 |
| U+03B0 | ΰ |
GREEK SMALL LETTER UPSILON WITH DIALYTIKA AND TONOS | υ, ̈, ́ |
U+03C5, U+0308, U+0301 |
| U+0587 | և |
ARMENIAN SMALL LIGATURE ECH YIWN | ե, ւ |
U+0565, U+0582 |
| U+1E96 | ẖ |
LATIN SMALL LETTER H WITH LINE BELOW | h, ̱ |
U+0068, U+0331 |
| U+1E97 | ẗ |
LATIN SMALL LETTER T WITH DIAERESIS | t, ̈ |
U+0074, U+0308 |
| U+1E98 | ẘ |
LATIN SMALL LETTER W WITH RING ABOVE | w, ̊ |
U+0077, U+030A |
| U+1E99 | ẙ |
LATIN SMALL LETTER Y WITH RING ABOVE | y, ̊ |
U+0079, U+030A |
| U+1E9A | ẚ |
LATIN SMALL LETTER A WITH RIGHT HALF RING | a, ʾ |
U+0061, U+02BE |
| U+1E9E | ẞ |
LATIN CAPITAL LETTER SHARP S | s, s |
U+0073, U+0073 |
| U+1F50 | ὐ |
GREEK SMALL LETTER UPSILON WITH PSILI | υ, ̓ |
U+03C5, U+0313 |
| U+1F52 | ὒ |
GREEK SMALL LETTER UPSILON WITH PSILI AND VARIA | υ, ̓, ̀ |
U+03C5, U+0313, U+0300 |
| U+1F54 | ὔ |
GREEK SMALL LETTER UPSILON WITH PSILI AND OXIA | υ, ̓, ́ |
U+03C5, U+0313, U+0301 |
| U+1F56 | ὖ |
GREEK SMALL LETTER UPSILON WITH PSILI AND PERISPOMENI | υ, ̓, ͂ |
U+03C5, U+0313, U+0342 |
| U+1F80 | ᾀ |
GREEK SMALL LETTER ALPHA WITH PSILI AND YPOGEGRAMMENI | ἀ, ι |
U+1F00, U+03B9 |
| U+1F81 | ᾁ |
GREEK SMALL LETTER ALPHA WITH DASIA AND YPOGEGRAMMENI | ἁ, ι |
U+1F01, U+03B9 |
| U+1F82 | ᾂ |
GREEK SMALL LETTER ALPHA WITH PSILI AND VARIA AND YPOGEGRAMMENI | ἂ, ι |
U+1F02, U+03B9 |
| U+1F83 | ᾃ |
GREEK SMALL LETTER ALPHA WITH DASIA AND VARIA AND YPOGEGRAMMENI | ἃ, ι |
U+1F03, U+03B9 |
| U+1F84 | ᾄ |
GREEK SMALL LETTER ALPHA WITH PSILI AND OXIA AND YPOGEGRAMMENI | ἄ, ι |
U+1F04, U+03B9 |
| U+1F85 | ᾅ |
GREEK SMALL LETTER ALPHA WITH DASIA AND OXIA AND YPOGEGRAMMENI | ἅ, ι |
U+1F05, U+03B9 |
| U+1F86 | ᾆ |
GREEK SMALL LETTER ALPHA WITH PSILI AND PERISPOMENI AND YPOGEGRAMMENI | ἆ, ι |
U+1F06, U+03B9 |
| U+1F87 | ᾇ |
GREEK SMALL LETTER ALPHA WITH DASIA AND PERISPOMENI AND YPOGEGRAMMENI | ἇ, ι |
U+1F07, U+03B9 |
| U+1F88 | ᾈ |
GREEK CAPITAL LETTER ALPHA WITH PSILI AND PROSGEGRAMMENI | ἀ, ι |
U+1F00, U+03B9 |
| U+1F89 | ᾉ |
GREEK CAPITAL LETTER ALPHA WITH DASIA AND PROSGEGRAMMENI | ἁ, ι |
U+1F01, U+03B9 |
| U+1F8A | ᾊ |
GREEK CAPITAL LETTER ALPHA WITH PSILI AND VARIA AND PROSGEGRAMMENI | ἂ, ι |
U+1F02, U+03B9 |
| U+1F8B | ᾋ |
GREEK CAPITAL LETTER ALPHA WITH DASIA AND VARIA AND PROSGEGRAMMENI | ἃ, ι |
U+1F03, U+03B9 |
| U+1F8C | ᾌ |
GREEK CAPITAL LETTER ALPHA WITH PSILI AND OXIA AND PROSGEGRAMMENI | ἄ, ι |
U+1F04, U+03B9 |
| U+1F8D | ᾍ |
GREEK CAPITAL LETTER ALPHA WITH DASIA AND OXIA AND PROSGEGRAMMENI | ἅ, ι |
U+1F05, U+03B9 |
| U+1F8E | ᾎ |
GREEK CAPITAL LETTER ALPHA WITH PSILI AND PERISPOMENI AND PROSGEGRAMMENI | ἆ, ι |
U+1F06, U+03B9 |
| U+1F8F | ᾏ |
GREEK CAPITAL LETTER ALPHA WITH DASIA AND PERISPOMENI AND PROSGEGRAMMENI | ἇ, ι |
U+1F07, U+03B9 |
| U+1F90 | ᾐ |
GREEK SMALL LETTER ETA WITH PSILI AND YPOGEGRAMMENI | ἠ, ι |
U+1F20, U+03B9 |
| U+1F91 | ᾑ |
GREEK SMALL LETTER ETA WITH DASIA AND YPOGEGRAMMENI | ἡ, ι |
U+1F21, U+03B9 |
| U+1F92 | ᾒ |
GREEK SMALL LETTER ETA WITH PSILI AND VARIA AND YPOGEGRAMMENI | ἢ, ι |
U+1F22, U+03B9 |
| U+1F93 | ᾓ |
GREEK SMALL LETTER ETA WITH DASIA AND VARIA AND YPOGEGRAMMENI | ἣ, ι |
U+1F23, U+03B9 |
| U+1F94 | ᾔ |
GREEK SMALL LETTER ETA WITH PSILI AND OXIA AND YPOGEGRAMMENI | ἤ, ι |
U+1F24, U+03B9 |
| U+1F95 | ᾕ |
GREEK SMALL LETTER ETA WITH DASIA AND OXIA AND YPOGEGRAMMENI | ἥ, ι |
U+1F25, U+03B9 |
| U+1F96 | ᾖ |
GREEK SMALL LETTER ETA WITH PSILI AND PERISPOMENI AND YPOGEGRAMMENI | ἦ, ι |
U+1F26, U+03B9 |
| U+1F97 | ᾗ |
GREEK SMALL LETTER ETA WITH DASIA AND PERISPOMENI AND YPOGEGRAMMENI | ἧ, ι |
U+1F27, U+03B9 |
| U+1F98 | ᾘ |
GREEK CAPITAL LETTER ETA WITH PSILI AND PROSGEGRAMMENI | ἠ, ι |
U+1F20, U+03B9 |
| U+1F99 | ᾙ |
GREEK CAPITAL LETTER ETA WITH DASIA AND PROSGEGRAMMENI | ἡ, ι |
U+1F21, U+03B9 |
| U+1F9A | ᾚ |
GREEK CAPITAL LETTER ETA WITH PSILI AND VARIA AND PROSGEGRAMMENI | ἢ, ι |
U+1F22, U+03B9 |
| U+1F9B | ᾛ |
GREEK CAPITAL LETTER ETA WITH DASIA AND VARIA AND PROSGEGRAMMENI | ἣ, ι |
U+1F23, U+03B9 |
| U+1F9C | ᾜ |
GREEK CAPITAL LETTER ETA WITH PSILI AND OXIA AND PROSGEGRAMMENI | ἤ, ι |
U+1F24, U+03B9 |
| U+1F9D | ᾝ |
GREEK CAPITAL LETTER ETA WITH DASIA AND OXIA AND PROSGEGRAMMENI | ἥ, ι |
U+1F25, U+03B9 |
| U+1F9E | ᾞ |
GREEK CAPITAL LETTER ETA WITH PSILI AND PERISPOMENI AND PROSGEGRAMMENI | ἦ, ι |
U+1F26, U+03B9 |
| U+1F9F | ᾟ |
GREEK CAPITAL LETTER ETA WITH DASIA AND PERISPOMENI AND PROSGEGRAMMENI | ἧ, ι |
U+1F27, U+03B9 |
| U+1FA0 | ᾠ |
GREEK SMALL LETTER OMEGA WITH PSILI AND YPOGEGRAMMENI | ὠ, ι |
U+1F60, U+03B9 |
| U+1FA1 | ᾡ |
GREEK SMALL LETTER OMEGA WITH DASIA AND YPOGEGRAMMENI | ὡ, ι |
U+1F61, U+03B9 |
| U+1FA2 | ᾢ |
GREEK SMALL LETTER OMEGA WITH PSILI AND VARIA AND YPOGEGRAMMENI | ὢ, ι |
U+1F62, U+03B9 |
| U+1FA3 | ᾣ |
GREEK SMALL LETTER OMEGA WITH DASIA AND VARIA AND YPOGEGRAMMENI | ὣ, ι |
U+1F63, U+03B9 |
| U+1FA4 | ᾤ |
GREEK SMALL LETTER OMEGA WITH PSILI AND OXIA AND YPOGEGRAMMENI | ὤ, ι |
U+1F64, U+03B9 |
| U+1FA5 | ᾥ |
GREEK SMALL LETTER OMEGA WITH DASIA AND OXIA AND YPOGEGRAMMENI | ὥ, ι |
U+1F65, U+03B9 |
| U+1FA6 | ᾦ |
GREEK SMALL LETTER OMEGA WITH PSILI AND PERISPOMENI AND YPOGEGRAMMENI | ὦ, ι |
U+1F66, U+03B9 |
| U+1FA7 | ᾧ |
GREEK SMALL LETTER OMEGA WITH DASIA AND PERISPOMENI AND YPOGEGRAMMENI | ὧ, ι |
U+1F67, U+03B9 |
| U+1FA8 | ᾨ |
GREEK CAPITAL LETTER OMEGA WITH PSILI AND PROSGEGRAMMENI | ὠ, ι |
U+1F60, U+03B9 |
| U+1FA9 | ᾩ |
GREEK CAPITAL LETTER OMEGA WITH DASIA AND PROSGEGRAMMENI | ὡ, ι |
U+1F61, U+03B9 |
| U+1FAA | ᾪ |
GREEK CAPITAL LETTER OMEGA WITH PSILI AND VARIA AND PROSGEGRAMMENI | ὢ, ι |
U+1F62, U+03B9 |
| U+1FAB | ᾫ |
GREEK CAPITAL LETTER OMEGA WITH DASIA AND VARIA AND PROSGEGRAMMENI | ὣ, ι |
U+1F63, U+03B9 |
| U+1FAC | ᾬ |
GREEK CAPITAL LETTER OMEGA WITH PSILI AND OXIA AND PROSGEGRAMMENI | ὤ, ι |
U+1F64, U+03B9 |
| U+1FAD | ᾭ |
GREEK CAPITAL LETTER OMEGA WITH DASIA AND OXIA AND PROSGEGRAMMENI | ὥ, ι |
U+1F65, U+03B9 |
| U+1FAE | ᾮ |
GREEK CAPITAL LETTER OMEGA WITH PSILI AND PERISPOMENI AND PROSGEGRAMMENI | ὦ, ι |
U+1F66, U+03B9 |
| U+1FAF | ᾯ |
GREEK CAPITAL LETTER OMEGA WITH DASIA AND PERISPOMENI AND PROSGEGRAMMENI | ὧ, ι |
U+1F67, U+03B9 |
| U+1FB2 | ᾲ |
GREEK SMALL LETTER ALPHA WITH VARIA AND YPOGEGRAMMENI | ὰ, ι |
U+1F70, U+03B9 |
| U+1FB3 | ᾳ |
GREEK SMALL LETTER ALPHA WITH YPOGEGRAMMENI | α, ι |
U+03B1, U+03B9 |
| U+1FB4 | ᾴ |
GREEK SMALL LETTER ALPHA WITH OXIA AND YPOGEGRAMMENI | ά, ι |
U+03AC, U+03B9 |
| U+1FB6 | ᾶ |
GREEK SMALL LETTER ALPHA WITH PERISPOMENI | α, ͂ |
U+03B1, U+0342 |
| U+1FB7 | ᾷ |
GREEK SMALL LETTER ALPHA WITH PERISPOMENI AND YPOGEGRAMMENI | α, ͂, ι |
U+03B1, U+0342, U+03B9 |
| U+1FBC | ᾼ |
GREEK CAPITAL LETTER ALPHA WITH PROSGEGRAMMENI | α, ι |
U+03B1, U+03B9 |
| U+1FC2 | ῂ |
GREEK SMALL LETTER ETA WITH VARIA AND YPOGEGRAMMENI | ὴ, ι |
U+1F74, U+03B9 |
| U+1FC3 | ῃ |
GREEK SMALL LETTER ETA WITH YPOGEGRAMMENI | η, ι |
U+03B7, U+03B9 |
| U+1FC4 | ῄ |
GREEK SMALL LETTER ETA WITH OXIA AND YPOGEGRAMMENI | ή, ι |
U+03AE, U+03B9 |
| U+1FC6 | ῆ |
GREEK SMALL LETTER ETA WITH PERISPOMENI | η, ͂ |
U+03B7, U+0342 |
| U+1FC7 | ῇ |
GREEK SMALL LETTER ETA WITH PERISPOMENI AND YPOGEGRAMMENI | η, ͂, ι |
U+03B7, U+0342, U+03B9 |
| U+1FCC | ῌ |
GREEK CAPITAL LETTER ETA WITH PROSGEGRAMMENI | η, ι |
U+03B7, U+03B9 |
| U+1FD2 | ῒ |
GREEK SMALL LETTER IOTA WITH DIALYTIKA AND VARIA | ι, ̈, ̀ |
U+03B9, U+0308, U+0300 |
| U+1FD3 | ΐ |
GREEK SMALL LETTER IOTA WITH DIALYTIKA AND OXIA | ι, ̈, ́ |
U+03B9, U+0308, U+0301 |
| U+1FD6 | ῖ |
GREEK SMALL LETTER IOTA WITH PERISPOMENI | ι, ͂ |
U+03B9, U+0342 |
| U+1FD7 | ῗ |
GREEK SMALL LETTER IOTA WITH DIALYTIKA AND PERISPOMENI | ι, ̈, ͂ |
U+03B9, U+0308, U+0342 |
| U+1FE2 | ῢ |
GREEK SMALL LETTER UPSILON WITH DIALYTIKA AND VARIA | υ, ̈, ̀ |
U+03C5, U+0308, U+0300 |
| U+1FE3 | ΰ |
GREEK SMALL LETTER UPSILON WITH DIALYTIKA AND OXIA | υ, ̈, ́ |
U+03C5, U+0308, U+0301 |
| U+1FE4 | ῤ |
GREEK SMALL LETTER RHO WITH PSILI | ρ, ̓ |
U+03C1, U+0313 |
| U+1FE6 | ῦ |
GREEK SMALL LETTER UPSILON WITH PERISPOMENI | υ, ͂ |
U+03C5, U+0342 |
| U+1FE7 | ῧ |
GREEK SMALL LETTER UPSILON WITH DIALYTIKA AND PERISPOMENI | υ, ̈, ͂ |
U+03C5, U+0308, U+0342 |
| U+1FF2 | ῲ |
GREEK SMALL LETTER OMEGA WITH VARIA AND YPOGEGRAMMENI | ὼ, ι |
U+1F7C, U+03B9 |
| U+1FF3 | ῳ |
GREEK SMALL LETTER OMEGA WITH YPOGEGRAMMENI | ω, ι |
U+03C9, U+03B9 |
| U+1FF4 | ῴ |
GREEK SMALL LETTER OMEGA WITH OXIA AND YPOGEGRAMMENI | ώ, ι |
U+03CE, U+03B9 |
| U+1FF6 | ῶ |
GREEK SMALL LETTER OMEGA WITH PERISPOMENI | ω, ͂ |
U+03C9, U+0342 |
| U+1FF7 | ῷ |
GREEK SMALL LETTER OMEGA WITH PERISPOMENI AND YPOGEGRAMMENI | ω, ͂, ι |
U+03C9, U+0342, U+03B9 |
| U+1FFC | ῼ |
GREEK CAPITAL LETTER OMEGA WITH PROSGEGRAMMENI | ω, ι |
U+03C9, U+03B9 |
| U+FB00 | ff |
LATIN SMALL LIGATURE FF | f, f |
U+0066, U+0066 |
| U+FB01 | fi |
LATIN SMALL LIGATURE FI | f, i |
U+0066, U+0069 |
| U+FB02 | fl |
LATIN SMALL LIGATURE FL | f, l |
U+0066, U+006C |
| U+FB03 | ffi |
LATIN SMALL LIGATURE FFI | f, f, i |
U+0066, U+0066, U+0069 |
| U+FB04 | ffl |
LATIN SMALL LIGATURE FFL | f, f, l |
U+0066, U+0066, U+006C |
| U+FB05 | ſt |
LATIN SMALL LIGATURE LONG S T | s, t |
U+0073, U+0074 |
| U+FB06 | st |
LATIN SMALL LIGATURE ST | s, t |
U+0073, U+0074 |
| U+FB13 | ﬓ |
ARMENIAN SMALL LIGATURE MEN NOW | մ, ն |
U+0574, U+0576 |
| U+FB14 | ﬔ |
ARMENIAN SMALL LIGATURE MEN ECH | մ, ե |
U+0574, U+0565 |
| U+FB15 | ﬕ |
ARMENIAN SMALL LIGATURE MEN INI | մ, ի |
U+0574, U+056B |
| U+FB16 | ﬖ |
ARMENIAN SMALL LIGATURE VEW NOW | վ, ն |
U+057E, U+0576 |
| U+FB17 | ﬗ |
ARMENIAN SMALL LIGATURE MEN XEH | մ, խ |
U+0574, U+056D |
The Unicode Consortium has made a huge effort better reflect and incorporate human diversity, including cultural practices. Here is the Consortium’s diversity report.
Emojis of mixed gender situations are now available, such as same sex families, holding hands, and kissing. The real kicker are Emoji combined sequences. Basically:
| Code Points | Recipe | Combined |
|---|---|---|
| U+1F469 U+200D U+2764 U+FE0F U+200D U+1F469 |
|
|
| U+1F468 U+200D U+1F468 U+200D U+1F467 U+200D U+1F466 |
|
|
Further, emojis now support skin color modifiers.
Five symbol modifier characters that provide for a range of skin tones for human emoji were released in Unicode Version 8.0 (mid-2015). These characters are based on the six tones of the Fitzpatrick scale, a recognized standard for dermatology (there are many examples of this scale online, such as FitzpatrickSkinType.pdf). The exact shades may vary between implementations. – Unicode Consortium’s Diversity report
| Code | Name | Samples |
|---|---|---|
| U+1F3FB | EMOJI MODIFIER FITZPATRICK TYPE-1-2 |
|
| U+1F3FC | EMOJI MODIFIER FITZPATRICK TYPE-3 |
|
| U+1F3FD | EMOJI MODIFIER FITZPATRICK TYPE-4 |
|
| U+1F3FE | EMOJI MODIFIER FITZPATRICK TYPE-5 |
|
| U+1F3FF | EMOJI MODIFIER FITZPATRICK TYPE-6 |
|
Just follow the desired Emoji with one of the skin color modifiers
\u{1F466}\u{1F3FE}.
![]() +
+
![]() →
→
![]()
![]()
Examples are written in JavaScript (ES6)
In general, characters designated the ID_START property may be used at the beggining of a variable name. Characters designated with the ID_CONTINUE property may be used after the first character of a variable.
function rand(μ,σ){ ... };
String.prototype.reverseⵑ = function(){..};
Number.prototype.isTrueɁ = function(){..};
var WhatDoesThisDoɁɁɁɁ = 42Here are some really creative variable names from Mathias Bynes
// How convenient!
var π = Math.PI;
// Sometimes, you just have to use the Bad Parts of JavaScript:
var ಠ_ಠ = eval;
// Code, Y U NO WORK?!
var ლ_ಠ益ಠ_ლ = 42;
// How about a JavaScript library for functional programming?
var λ = function() {};
// Obfuscate boring variable names for great justice
var \u006C\u006F\u006C\u0077\u0061\u0074 = 'heh';
// …or just make up random ones
var Ꙭൽↈⴱ = 'huh';
// While perfectly valid, this doesn’t work in most browsers:
var foo\u200Cbar = 42;
// This is *not* a bitwise left shift (`<<`):
var 〱〱 = 2;
// This is, though:
〱〱 << 〱〱; // 8
// Give yourself a discount:
var price_9̶9̶_89 = 'cheap';
// Fun with Roman numerals
var Ⅳ = 4;
var Ⅴ = 5;
Ⅳ + Ⅴ; // 9
// Cthulhu was here
var Hͫ̆̒̐ͣ̊̄ͯ͗͏̵̗̻̰̠̬͝ͅE̴̷̬͎̱̘͇͍̾ͦ͊͒͊̓̓̐_̫̠̱̩̭̤͈̑̎̋ͮͩ̒͑̾͋͘Ç̳͕̯̭̱̲̣̠̜͋̍O̴̦̗̯̹̼ͭ̐ͨ̊̈͘͠M̶̝̠̭̭̤̻͓͑̓̊ͣͤ̎͟͠E̢̞̮̹͍̞̳̣ͣͪ͐̈T̡̯̳̭̜̠͕͌̈́̽̿ͤ̿̅̑Ḧ̱̱̺̰̳̹̘̰́̏ͪ̂̽͂̀͠ = 'Zalgo';And here’s some Unicode CSS Classes from David Walsh
<!-- place this within the document head -->
<meta charset="UTF-8" />
<!-- error message -->
<div class="ಠ_ಠ">You do not have access to this page.</div>
<!-- success message -->
<div class="❤">Your changes have been saved successfully!</div>If you want to rename all your HTML tags to what appears as nothing, the following script is just what your looking for.
Do note however that HTML does not support all unicode characters.
// U+1160 HANGUL JUNGSEONG FILLER
transformAllTags('ᅠ');
// An actual HTML element node designed to look like a comment node, using the U+01C3 LATIN LETTER RETROFLEX CLICK
// <ǃ-- name="viewport" content="width=device-width"></ǃ-->
transformAllTags('ǃ--');
// or even <ᅠ⃝
transformAllTags('\u{1160}\u{20dd}');
// and for a bonus, all existing tag names will have each character ensquared. h⃞t⃞m⃞l⃞
transformAllTags();
function transformAllTags (newName){
// querySelectorAll doesn't actually return an array.
Array.from(document.querySelectorAll('*'))
.forEach(function(x){
transformTag(x, newName);
});
}
function wonky(str){
return str.split('').join('\u{20de}') + '\u{20de}';
}
function transformTag(tagIdOrElem, tagType){
var elem = (tagIdOrElem instanceof HTMLElement) ? tagIdOrElem : document.getElementById(tagIdOrElem);
if(!elem || !(elem instanceof HTMLElement))return;
var children = elem.childNodes;
var parent = elem.parentNode;
var newNode = document.createElement(tagType||wonky(elem.tagName));
for(var a=0;a<elem.attributes.length;a++){
newNode.setAttribute(elem.attributes[a].nodeName, elem.attributes[a].value);
}
for(var i= 0,clen=children.length;i<clen;i++){
newNode.appendChild(children[0]); //0...always point to the first non-moved element
}
newNode.style.cssText = elem.style.cssText;
parent.replaceChild(newNode,elem);
}Here is what it does support:
function testBegin(str){
try{
eval(`document.createElement( '${str}' );`)
return true;
}
catch(e){ return false; }
}
function testContinue(str){
try{
eval(`document.createElement( 'a${str}' );`)
return true;
}
catch(e){ return false; }
}And heres some basic results
// Test if dashes can start an HTML Tag
> testBegin('-')
< false
> testContinue('-')
< true
> testBegin('ᅠ-') // Prepend dash with U+1160 HANGUL JUNGSEONG FILLER
< trueA single TrueType / OpenType font format cannot cover all UTF-8 characters as there is a hard limit of 65535 glyphs in a font. Since there are over 1.1 million UTF-8 glphys, you will need to use a font-family to cover them all. - https://en.wikipedia.org/wiki/Unicode_font#List_of_Unicode_fonts - http://www.unifont.org/fontguide/
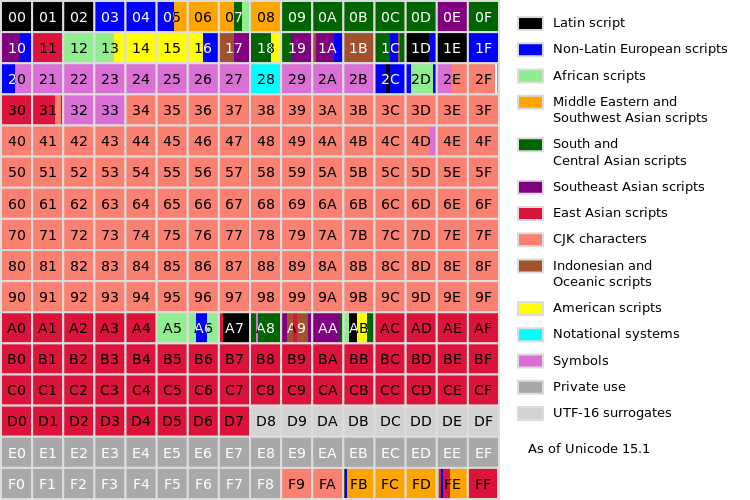
The Chinese, Japanese and Korean (CJK) scripts share a common background, collectively known as CJK characters. In the process called Han unification, the common (shared) characters were identified and named “CJK Unified Ideographs”.
The Unicode standard arranges groups of characters together in blocks. This is the complete list of blocks across all 17 planes.
| Name | From | To | # Codepoints |
|---|---|---|---|
| Basic Latin | U+0000 | U+007F | (128) |
| Latin-1 Supplement | U+0080 | U+00FF | (128) |
| Latin Extended-A | U+0100 | U+017F | (128) |
| Latin Extended-B | U+0180 | U+024F | (208) |
| IPA Extensions | U+0250 | U+02AF | (96) |
| Spacing Modifier Letters | U+02B0 | U+02FF | (80) |
| Combining Diacritical Marks | U+0300 | U+036F | (112) |
| Greek and Coptic | U+0370 | U+03FF | (135) |
| Cyrillic | U+0400 | U+04FF | (256) |
| Cyrillic Supplement | U+0500 | U+052F | (48) |
| Armenian | U+0530 | U+058F | (89) |
| Hebrew | U+0590 | U+05FF | (87) |
| Arabic | U+0600 | U+06FF | (255) |
| Syriac | U+0700 | U+074F | (77) |
| Arabic Supplement | U+0750 | U+077F | (48) |
| Thaana | U+0780 | U+07BF | (50) |
| NKo | U+07C0 | U+07FF | (59) |
| Samaritan | U+0800 | U+083F | (61) |
| Mandaic | U+0840 | U+085F | (29) |
| Arabic Extended-A | U+08A0 | U+08FF | (50) |
| Devanagari | U+0900 | U+097F | (128) |
| Bengali | U+0980 | U+09FF | (93) |
| Gurmukhi | U+0A00 | U+0A7F | (79) |
| Gujarati | U+0A80 | U+0AFF | (85) |
| Oriya | U+0B00 | U+0B7F | (90) |
| Tamil | U+0B80 | U+0BFF | (72) |
| Telugu | U+0C00 | U+0C7F | (96) |
| Kannada | U+0C80 | U+0CFF | (87) |
| Malayalam | U+0D00 | U+0D7F | (100) |
| Sinhala | U+0D80 | U+0DFF | (90) |
| Thai | U+0E00 | U+0E7F | (87) |
| Lao | U+0E80 | U+0EFF | (67) |
| Tibetan | U+0F00 | U+0FFF | (211) |
| Myanmar | U+1000 | U+109F | (160) |
| Georgian | U+10A0 | U+10FF | (88) |
| Hangul Jamo | U+1100 | U+11FF | (256) |
| Ethiopic | U+1200 | U+137F | (358) |
| Ethiopic Supplement | U+1380 | U+139F | (26) |
| Cherokee | U+13A0 | U+13FF | (92) |
| Unified Canadian Aboriginal Syllabics | U+1400 | U+167F | (640) |
| Ogham | U+1680 | U+169F | (29) |
| Runic | U+16A0 | U+16FF | (89) |
| Tagalog | U+1700 | U+171F | (20) |
| Hanunoo | U+1720 | U+173F | (23) |
| Buhid | U+1740 | U+175F | (20) |
| Tagbanwa | U+1760 | U+177F | (18) |
| Khmer | U+1780 | U+17FF | (114) |
| Mongolian | U+1800 | U+18AF | (156) |
| Unified Canadian Aboriginal Syllabics Extended | U+18B0 | U+18FF | (70) |
| Limbu | U+1900 | U+194F | (68) |
| Tai Le | U+1950 | U+197F | (35) |
| New Tai Lue | U+1980 | U+19DF | (83) |
| Khmer Symbols | U+19E0 | U+19FF | (32) |
| Buginese | U+1A00 | U+1A1F | (30) |
| Tai Tham | U+1A20 | U+1AAF | (127) |
| Combining Diacritical Marks Extended | U+1AB0 | U+1AFF | (15) |
| Balinese | U+1B00 | U+1B7F | (121) |
| Sundanese | U+1B80 | U+1BBF | (64) |
| Batak | U+1BC0 | U+1BFF | (56) |
| Lepcha | U+1C00 | U+1C4F | (74) |
| Ol Chiki | U+1C50 | U+1C7F | (48) |
| Sundanese Supplement | U+1CC0 | U+1CCF | (8) |
| Vedic Extensions | U+1CD0 | U+1CFF | (41) |
| Phonetic Extensions | U+1D00 | U+1D7F | (128) |
| Phonetic Extensions Supplement | U+1D80 | U+1DBF | (64) |
| Combining Diacritical Marks Supplement | U+1DC0 | U+1DFF | (58) |
| Latin Extended Additional | U+1E00 | U+1EFF | (256) |
| Greek Extended | U+1F00 | U+1FFF | (233) |
| General Punctuation | U+2000 | U+206F | (111) |
| Superscripts and Subscripts | U+2070 | U+209F | (42) |
| Currency Symbols | U+20A0 | U+20CF | (31) |
| Combining Diacritical Marks for Symbols | U+20D0 | U+20FF | (33) |
| Letterlike Symbols | U+2100 | U+214F | (80) |
| Number Forms | U+2150 | U+218F | (60) |
| Arrows | U+2190 | U+21FF | (112) |
| Mathematical Operators | U+2200 | U+22FF | (256) |
| Miscellaneous Technical | U+2300 | U+23FF | (251) |
| Control Pictures | U+2400 | U+243F | (39) |
| Optical Character Recognition | U+2440 | U+245F | (11) |
| Enclosed Alphanumerics | U+2460 | U+24FF | (160) |
| Box Drawing | U+2500 | U+257F | (128) |
| Block Elements | U+2580 | U+259F | (32) |
| Geometric Shapes | U+25A0 | U+25FF | (96) |
| Miscellaneous Symbols | U+2600 | U+26FF | (256) |
| Dingbats | U+2700 | U+27BF | (192) |
| Miscellaneous Mathematical Symbols-A | U+27C0 | U+27EF | (48) |
| Supplemental Arrows-A | U+27F0 | U+27FF | (16) |
| Braille Patterns | U+2800 | U+28FF | (256) |
| Supplemental Arrows-B | U+2900 | U+297F | (128) |
| Miscellaneous Mathematical Symbols-B | U+2980 | U+29FF | (128) |
| Supplemental Mathematical Operators | U+2A00 | U+2AFF | (256) |
| Miscellaneous Symbols and Arrows | U+2B00 | U+2BFF | (206) |
| Glagolitic | U+2C00 | U+2C5F | (94) |
| Latin Extended-C | U+2C60 | U+2C7F | (32) |
| Coptic | U+2C80 | U+2CFF | (123) |
| Georgian Supplement | U+2D00 | U+2D2F | (40) |
| Tifinagh | U+2D30 | U+2D7F | (59) |
| Ethiopic Extended | U+2D80 | U+2DDF | (79) |
| Cyrillic Extended-A | U+2DE0 | U+2DFF | (32) |
| Supplemental Punctuation | U+2E00 | U+2E7F | (67) |
| CJK Radicals Supplement | U+2E80 | U+2EFF | (115) |
| Kangxi Radicals | U+2F00 | U+2FDF | (214) |
| Ideographic Description Characters | U+2FF0 | U+2FFF | (12) |
| CJK Symbols and Punctuation | U+3000 | U+303F | (64) |
| Hiragana | U+3040 | U+309F | (93) |
| Katakana | U+30A0 | U+30FF | (96) |
| Bopomofo | U+3100 | U+312F | (41) |
| Hangul Compatibility Jamo | U+3130 | U+318F | (94) |
| Kanbun | U+3190 | U+319F | (16) |
| Bopomofo Extended | U+31A0 | U+31BF | (27) |
| CJK Strokes | U+31C0 | U+31EF | (36) |
| Katakana Phonetic Extensions | U+31F0 | U+31FF | (16) |
| Enclosed CJK Letters and Months | U+3200 | U+32FF | (254) |
| CJK Compatibility | U+3300 | U+33FF | (256) |
| CJK Unified Ideographs Extension A | U+3400 | U+4DBF | (6191) |
| Yijing Hexagram Symbols | U+4DC0 | U+4DFF | (64) |
| CJK Unified Ideographs | U+4E00 | U+9FFF | (20941) |
| Yi Syllables | U+A000 | U+A48F | (1165) |
| Yi Radicals | U+A490 | U+A4CF | (55) |
| Lisu | U+A4D0 | U+A4FF | (48) |
| Vai | U+A500 | U+A63F | (300) |
| Cyrillic Extended-B | U+A640 | U+A69F | (96) |
| Bamum | U+A6A0 | U+A6FF | (88) |
| Modifier Tone Letters | U+A700 | U+A71F | (32) |
| Latin Extended-D | U+A720 | U+A7FF | (159) |
| Syloti Nagri | U+A800 | U+A82F | (44) |
| Common Indic Number Forms | U+A830 | U+A83F | (10) |
| Phags-pa | U+A840 | U+A87F | (56) |
| Saurashtra | U+A880 | U+A8DF | (81) |
| Devanagari Extended | U+A8E0 | U+A8FF | (30) |
| Kayah Li | U+A900 | U+A92F | (48) |
| Rejang | U+A930 | U+A95F | (37) |
| Hangul Jamo Extended-A | U+A960 | U+A97F | (29) |
| Javanese | U+A980 | U+A9DF | (91) |
| Myanmar Extended-B | U+A9E0 | U+A9FF | (31) |
| Cham | U+AA00 | U+AA5F | (83) |
| Myanmar Extended-A | U+AA60 | U+AA7F | (32) |
| Tai Viet | U+AA80 | U+AADF | (72) |
| Meetei Mayek Extensions | U+AAE0 | U+AAFF | (23) |
| Ethiopic Extended-A | U+AB00 | U+AB2F | (32) |
| Latin Extended-E | U+AB30 | U+AB6F | (54) |
| Cherokee Supplement | U+AB70 | U+ABBF | (80) |
| Meetei Mayek | U+ABC0 | U+ABFF | (56) |
| Hangul Syllables | U+AC00 | U+D7AF | (2) |
| Hangul Jamo Extended-B | U+D7B0 | U+D7FF | (72) |
| High Surrogates | U+D800 | U+DB7F | (2) |
| High Private Use Surrogates | U+DB80 | U+DBFF | (2) |
| Low Surrogates | U+DC00 | U+DFFF | (2) |
| Private Use Area | U+E000 | U+F8FF | (2) |
| CJK Compatibility Ideographs | U+F900 | U+FAFF | (472) |
| Alphabetic Presentation Forms | U+FB00 | U+FB4F | (58) |
| Arabic Presentation Forms-A | U+FB50 | U+FDFF | (643) |
| Variation Selectors | U+FE00 | U+FE0F | (16) |
| Vertical Forms | U+FE10 | U+FE1F | (10) |
| Combining Half Marks | U+FE20 | U+FE2F | (16) |
| CJK Compatibility Forms | U+FE30 | U+FE4F | (32) |
| Small Form Variants | U+FE50 | U+FE6F | (26) |
| Arabic Presentation Forms-B | U+FE70 | U+FEFF | (141) |
| Halfwidth and Fullwidth Forms | U+FF00 | U+FFEF | (225) |
| Specials | U+FFF0 | U+FFFF | (7) |
| Linear B Syllabary | U+10000 | U+1007F | (88) |
| Linear B Ideograms | U+10080 | U+100FF | (123) |
| Aegean Numbers | U+10100 | U+1013F | (57) |
| Ancient Greek Numbers | U+10140 | U+1018F | (77) |
| Ancient Symbols | U+10190 | U+101CF | (13) |
| Phaistos Disc | U+101D0 | U+101FF | (46) |
| Lycian | U+10280 | U+1029F | (29) |
| Carian | U+102A0 | U+102DF | (49) |
| Coptic Epact Numbers | U+102E0 | U+102FF | (28) |
| Old Italic | U+10300 | U+1032F | (36) |
| Gothic | U+10330 | U+1034F | (27) |
| Old Permic | U+10350 | U+1037F | (43) |
| Ugaritic | U+10380 | U+1039F | (31) |
| Old Persian | U+103A0 | U+103DF | (50) |
| Deseret | U+10400 | U+1044F | (80) |
| Shavian | U+10450 | U+1047F | (48) |
| Osmanya | U+10480 | U+104AF | (40) |
| Elbasan | U+10500 | U+1052F | (40) |
| Caucasian Albanian | U+10530 | U+1056F | (53) |
| Linear A | U+10600 | U+1077F | (341) |
| Cypriot Syllabary | U+10800 | U+1083F | (55) |
| Imperial Aramaic | U+10840 | U+1085F | (31) |
| Palmyrene | U+10860 | U+1087F | (32) |
| Nabataean | U+10880 | U+108AF | (40) |
| Hatran | U+108E0 | U+108FF | (26) |
| Phoenician | U+10900 | U+1091F | (29) |
| Lydian | U+10920 | U+1093F | (27) |
| Meroitic Hieroglyphs | U+10980 | U+1099F | (32) |
| Meroitic Cursive | U+109A0 | U+109FF | (90) |
| Kharoshthi | U+10A00 | U+10A5F | (65) |
| Old South Arabian | U+10A60 | U+10A7F | (32) |
| Old North Arabian | U+10A80 | U+10A9F | (32) |
| Manichaean | U+10AC0 | U+10AFF | (51) |
| Avestan | U+10B00 | U+10B3F | (61) |
| Inscriptional Parthian | U+10B40 | U+10B5F | (30) |
| Inscriptional Pahlavi | U+10B60 | U+10B7F | (27) |
| Psalter Pahlavi | U+10B80 | U+10BAF | (29) |
| Old Turkic | U+10C00 | U+10C4F | (73) |
| Old Hungarian | U+10C80 | U+10CFF | (108) |
| Rumi Numeral Symbols | U+10E60 | U+10E7F | (31) |
| Brahmi | U+11000 | U+1107F | (109) |
| Kaithi | U+11080 | U+110CF | (66) |
| Sora Sompeng | U+110D0 | U+110FF | (35) |
| Chakma | U+11100 | U+1114F | (67) |
| Mahajani | U+11150 | U+1117F | (39) |
| Sharada | U+11180 | U+111DF | (94) |
| Sinhala Archaic Numbers | U+111E0 | U+111FF | (20) |
| Khojki | U+11200 | U+1124F | (61) |
| Multani | U+11280 | U+112AF | (38) |
| Khudawadi | U+112B0 | U+112FF | (69) |
| Grantha | U+11300 | U+1137F | (85) |
| Tirhuta | U+11480 | U+114DF | (82) |
| Siddham | U+11580 | U+115FF | (92) |
| Modi | U+11600 | U+1165F | (79) |
| Takri | U+11680 | U+116CF | (66) |
| Ahom | U+11700 | U+1173F | (57) |
| Warang Citi | U+118A0 | U+118FF | (84) |
| Pau Cin Hau | U+11AC0 | U+11AFF | (57) |
| Cuneiform | U+12000 | U+123FF | (922) |
| Cuneiform Numbers and Punctuation | U+12400 | U+1247F | (116) |
| Early Dynastic Cuneiform | U+12480 | U+1254F | (196) |
| Egyptian Hieroglyphs | U+13000 | U+1342F | (1071) |
| Anatolian Hieroglyphs | U+14400 | U+1467F | (583) |
| Bamum Supplement | U+16800 | U+16A3F | (569) |
| Mro | U+16A40 | U+16A6F | (43) |
| Bassa Vah | U+16AD0 | U+16AFF | (36) |
| Pahawh Hmong | U+16B00 | U+16B8F | (127) |
| Miao | U+16F00 | U+16F9F | (133) |
| Kana Supplement | U+1B000 | U+1B0FF | (2) |
| Duployan | U+1BC00 | U+1BC9F | (143) |
| Shorthand Format Controls | U+1BCA0 | U+1BCAF | (4) |
| Byzantine Musical Symbols | U+1D000 | U+1D0FF | (246) |
| Musical Symbols | U+1D100 | U+1D1FF | (231) |
| Ancient Greek Musical Notation | U+1D200 | U+1D24F | (70) |
| Tai Xuan Jing Symbols | U+1D300 | U+1D35F | (87) |
| Counting Rod Numerals | U+1D360 | U+1D37F | (18) |
| Mathematical Alphanumeric Symbols | U+1D400 | U+1D7FF | (996) |
| Sutton SignWriting | U+1D800 | U+1DAAF | (672) |
| Mende Kikakui | U+1E800 | U+1E8DF | (213) |
| Arabic Mathematical Alphabetic Symbols | U+1EE00 | U+1EEFF | (143) |
| Mahjong Tiles | U+1F000 | U+1F02F | (44) |
| Domino Tiles | U+1F030 | U+1F09F | (100) |
| Playing Cards | U+1F0A0 | U+1F0FF | (82) |
| Enclosed Alphanumeric Supplement | U+1F100 | U+1F1FF | (173) |
| Enclosed Ideographic Supplement | U+1F200 | U+1F2FF | (57) |
| Miscellaneous Symbols and Pictographs | U+1F300 | U+1F5FF | (766) |
| Emoticons | U+1F600 | U+1F64F | (80) |
| Ornamental Dingbats | U+1F650 | U+1F67F | (48) |
| Transport and Map Symbols | U+1F680 | U+1F6FF | (98) |
| Alchemical Symbols | U+1F700 | U+1F77F | (116) |
| Geometric Shapes Extended | U+1F780 | U+1F7FF | (85) |
| Supplemental Arrows-C | U+1F800 | U+1F8FF | (148) |
| Supplemental Symbols and Pictographs | U+1F900 | U+1F9FF | (15) |
| CJK Unified Ideographs Extension B | U+20000 | U+2A6DF | (42676) |
| CJK Unified Ideographs Extension C | U+2A700 | U+2B73F | (60) |
| CJK Unified Ideographs Extension D | U+2B740 | U+2B81F | (27) |
| CJK Unified Ideographs Extension E | U+2B820 | U+2CEAF | (2) |
| CJK Compatibility Ideographs Supplement | U+2F800 | U+2FA1F | (542) |
| Tags | U+E0000 | U+E007F | (97) |
| Variation Selectors Supplement | U+E0100 | U+E01EF | (240) |
| Supplementary Private Use Area-A | U+F0000 | U+FFFFF | (4) |
| Supplementary Private Use Area-B | U+100000 | U+10FFFF | (4) |
The Unicode Standard set forth the following fundamental principles:
Note: Principle descriptions are from codepoints.net
See the Awesome Unicode contribution guide for details on how to contribute.
See the Code of Conduct for details. Basically it comes down to: >In the interest of fostering an open and welcoming environment, we as contributors and maintainers pledge to making participation in our project and our community a harassment-free experience for everyone, regardless of age, body size, disability, ethnicity, gender identity and expression, level of experience, nationality, personal appearance, race, religion, or sexual identity and orientation.

To the extent possible under law, the contributors have waived all copyright and related or neighboring rights to this work. See the license file for details.